ポイント
- 会話内容や話者同士の関係性、性格も考慮した身体動作(ジェスチャー)を、対話音声から生成する技術を開発
- ユーザの話者としてのジェスチャーや聞き手としての反応も踏まえて、話し相手の自然なジェスチャーをAIがリアルタイムに自動生成
- 対話型AIエージェントのコミュニケーション技術への活用に期待
概要
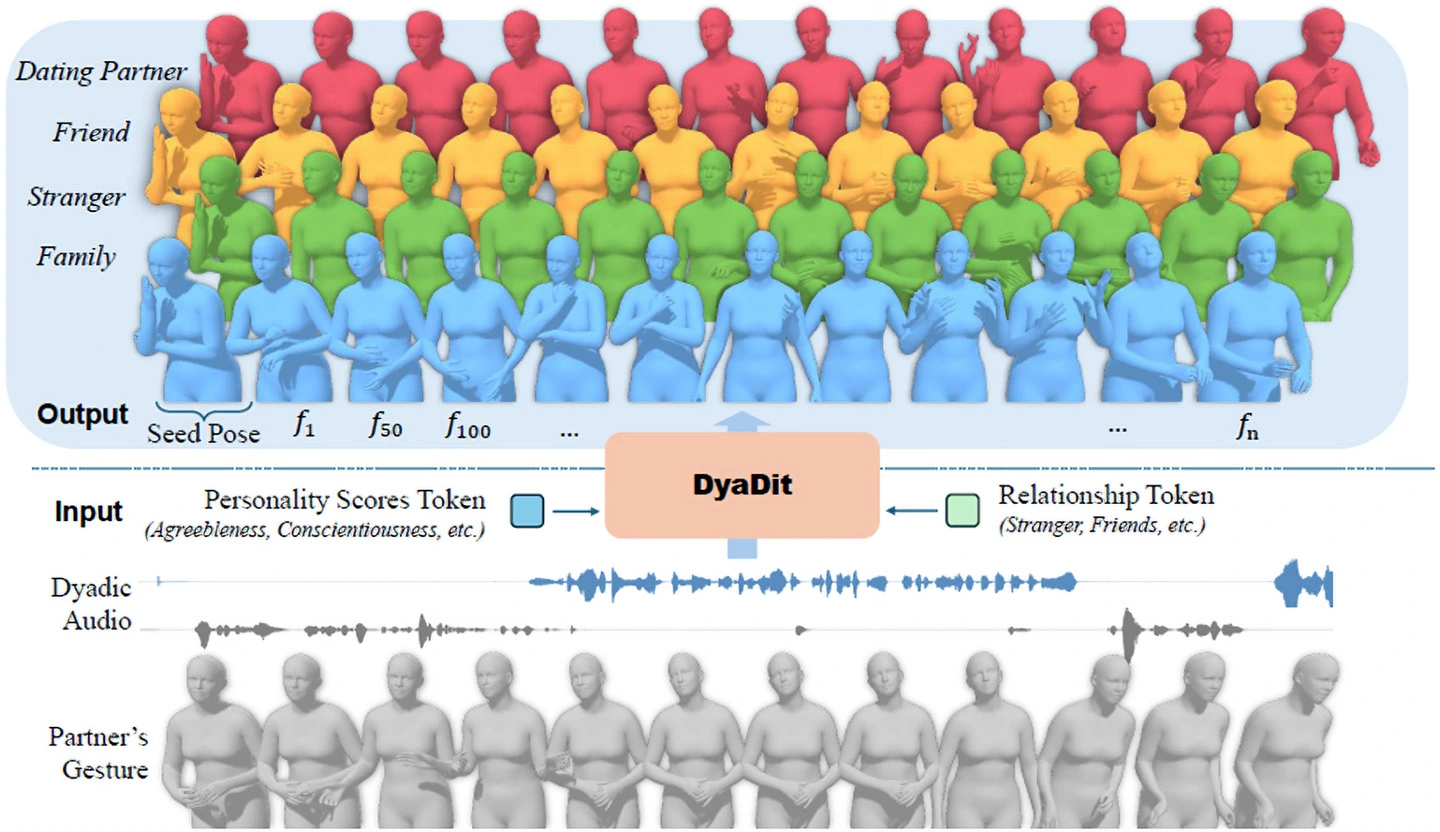
東京科学大学(Science Tokyo) 情報理工学院 情報工学系の小池英樹教授、カーネギーメロン大学 ロボティクス研究所の木谷クリス(Kris Kitani)教授らの研究チームは、対話音声から自然な身体動作(ジェスチャー)を生成する深層学習モデル[用語1]「DyaDiT」を開発しました。DyaDiTは、会話中の二者の音声情報に加え、話者同士の関係性や性格特性といった社会的コンテキストを考慮することで、ユーザが話している時の聞き手としての自然なリアクションジェスチャーを生成することができます。
人と人とのコミュニケーションにおいては、言語や音声などの情報だけでなく、身振りやうなずきなどの身体動作が重要な役割を果たしています。しかし、従来のジェスチャー生成技術の多くは、単一話者の音声からジェスチャーを生成することを前提としており、話し相手との相互作用や社会的関係性を十分に考慮することはできませんでした。そのため、生成される動作は画一的なものであることが多く、実際の対話のような自然な振る舞いを再現することは困難でした。
これに対し、本研究で開発したDyaDiTは、二者の音声を同時に解析することで対話の相互作用を理解し、さらにユーザ自身のジェスチャーや反応を入力として利用することで、話し相手として相応しいジェスチャーをリアルタイムに生成することを可能にしました。本技術により、デジタルヒューマンや対話型AIエージェントが、より自然で社会的に適切な振る舞いを伴ったコミュニケーションを行うことが期待されます。
本成果は、2026年6月3日(現地時間)から開催されたコンピュータービジョン(CV)に関する国際会議「The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026」で発表されました。
背景
人同士が対話をする際、言葉による情報だけでなく、身振りやうなずきなどの身体動作(ジェスチャー)がコミュニケーションにおける重要な役割を果たすことが知られています。対話エージェントが人間らしい自然なジェスチャーを伴って応答できるようになれば、より円滑で豊かなコミュニケーションの実現が期待されます。こうした背景から、対話エージェントに向けたジェスチャー生成技術の開発が求められています。しかし、従来のジェスチャー生成技術の多くは、単一話者の音声のみを入力としてジェスチャーを生成することを前提としており、話し相手との相互作用や社会的関係性を十分に考慮することができませんでした。また、実際の対話では二者の発話が重なったり、自分の反応に応じて相手の動作が変化したりするため、自然な対話ジェスチャーを生成することは容易ではありませんでした。
研究成果
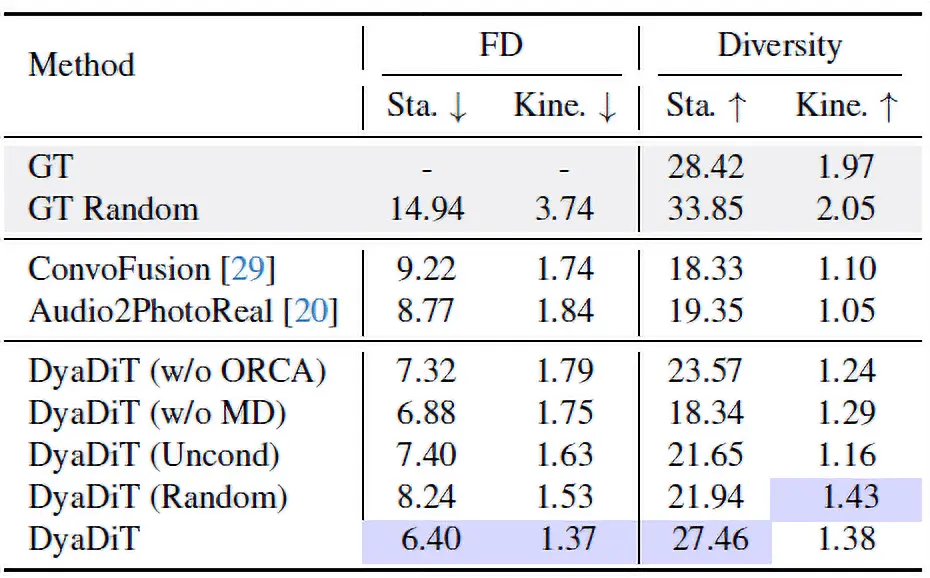
本研究では、話し相手の自然なジェスチャーを、対話音声から生成する深層学習モデル「DyaDiT」を開発しました(図1)。本モデルは、二者の対話音声に加えて、話者同士の関係性や性格特性といった社会的情報を入力として利用することで、ユーザが話している時の聞き手として相応しいリアクションジェスチャーを生成することができます。さらに、ユーザのジェスチャーや反応を入力として利用することで、対話の状況に応じた自然な動作を生成することを可能にしました。実験の結果、本手法は従来の手法と比較して、より自然で多様なジェスチャーを生成できることを示しました(図2-図4)。
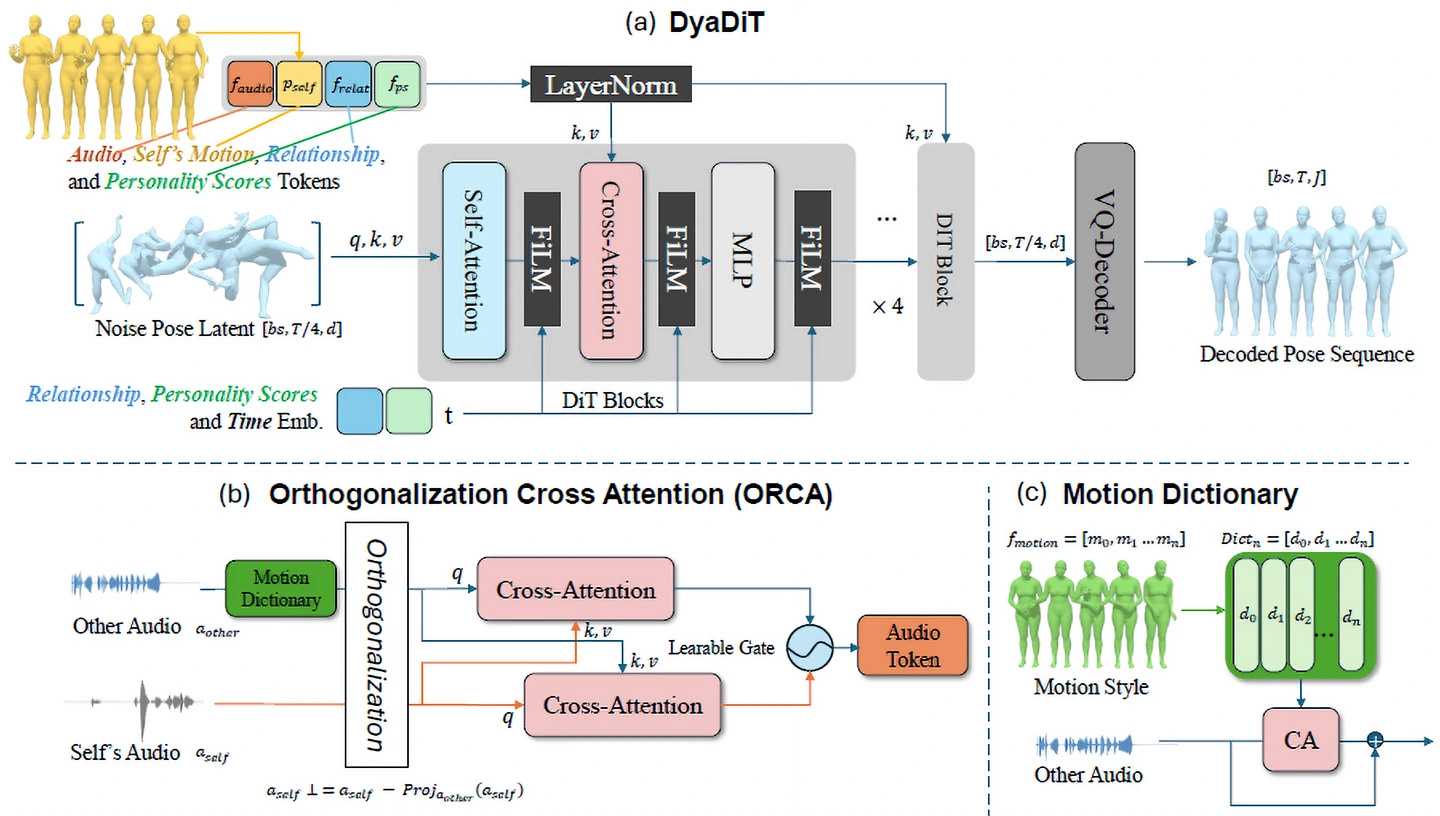
(a)対話音声(Audio)、動作(Motion)、関係性(Relationship)、および性格情報(Personality Scores)を条件としてジェスチャー(Decoded Pose Sequence)を生成する拡散トランスフォーマー。
(b)二者の音声(Self’s Audio、Other Audio)を分離して相互作用を捉えるORCAモジュール。
(c)動作スタイルを表現するMotion Dictionary。
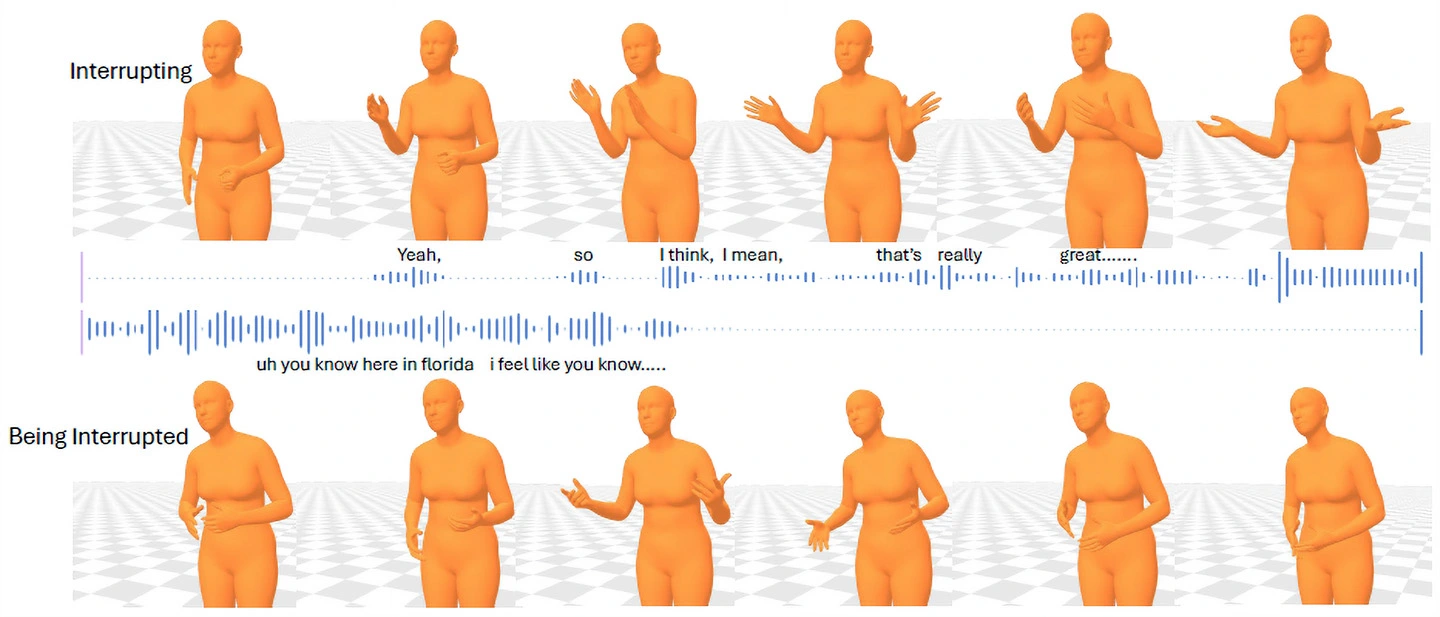
社会的インパクト
本研究で開発した技術は、デジタルヒューマンや対話型AIエージェントが人間とより自然にコミュニケーションを行うための基盤技術として活用されることが期待されます。例えば、オンライン会議、バーチャルアシスタント、教育支援システム、メタバース空間におけるアバターなどに応用することで、これまでより自然で臨場感のある対話体験を実現することが可能になります。また、人間同士の対話行動を理解・再現する研究の発展にも寄与し、人とAIが円滑に共存する社会の実現に貢献することが期待されます。
今後の展開
今後は、本研究で開発したモデルを拡張し、上半身のジェスチャーだけでなく、全身動作や表情などを含めたより豊かな対話行動の生成を目指します。また、大規模言語モデルなどの対話AIと統合することで、言語理解と身体動作を一体化したより自然なデジタルヒューマンの実現を目指します。さらに、人とAIが自然にコミュニケーションできるインタフェースの実現に向けて、教育、接客、遠隔コミュニケーションなど、さまざまな分野への応用を検討していきます。
付記
本研究は、科学技術振興機構(JST)ASPIRE(先端国際共同研究推進事業)JPMJAP2404の支援を受けて実施されました。また、東京科学大学「インタラクティブ知能協働研究拠点」活動の一部として実施されました。
用語説明
- [用語1]
- 深層学習モデル:人間の神経細胞の仕組みをモデルとしたニューラルネットワークを多層化した機械学習システム。
- [用語2]
- FD(Fréchet Distance)指標:AIが生成した動作と実際の人間の動作との近さを評価するための指標。FDが低いほど、生成結果がより自然で高品質であることを示す。
論文情報
- タイトル:
- DyaDiT: A Multi-Modal Diffusion Transformer for Socially Favorable Dyadic Gesture Generation
- 著者:
- Yichen Peng, Jyun-Ting Song, Siyeol Jung, Ruofan Liu, Haiyang Liu, Xuangeng Chu, Ruicong Liu, Erwin Wu, Hideki Koike, Kris Kitani
- 発表日:
- 2026年6月5日(現地時間)
研究者プロフィール
小池 英樹 Hideki Koike
東京科学大学 情報理工学院 情報工学系 教授
研究分野:ヒューマンコンピュータインタラクション
ホウ・イシン Yichen Peng
東京科学大学 情報理工学院 情報工学系 特任助教
研究分野:ヒューマンコンピュータインタラクション
ソン・ジュンテイ Jyun-Ting Song
カーネギーメロン大学(CMU)ロボティクス研究所 博士課程学生
研究分野:コンピュータービジョン、ロボティクス
シヨル・ジョン Siyeol Jung
蔚山国立科学技術大学(UNIST)
Interactive Multimodal Machine Learning lab 修士課程学生
研究分野:マルチモダリティ学習、自然言語処理
リュウ・ローハン Ruofan Liu
東京科学大学 情報理工学院 情報工学系 博士後期課程学生
研究分野:ヒューマンコンピュータインタラクション
リュウ・ハイヤン Haiyang Liu
東京大学 大学院情報理工学系研究科 博士後期課程学生
研究分野:生成モデル
チュ・センコウ Xuangeng Chu
東京大学 大学院情報理工学系研究科 博士後期課程学生
研究分野:生成モデル
リュウ・エイソウ Ruicong Liu
東京大学 大学院情報理工学系研究科 博士後期課程学生
研究分野:身体性知能、生成モデル
ウー・エアウイン Erwin Wu
東京科学大学 情報理工学院 情報工学系 特任准教授
研究分野:ヒューマンコンピュータインタラクション
木谷 クリス Kris Kitani
カーネギーメロン大学(CMU) ロボティクス研究所 准教授
研究分野:ロボティクス、コンピュータービジョン